Quick Introduction to Federated Learning
Apr 05, 2025 | 5 min read
A short technical introduction to federated learning, a framework for privacy preserving machine learning.
Centralized Machine Learning
In traditional machine learning, all the data is stored in one place and computation all happens on one computer (roughly speaking). The machine learning problem is formalized as minimizing a loss function with respect to the weights.

And the loss function can be optimized using gradient descent. Each update is:

The weights are updated iteratively until convergence or after a certain amount of times.
Privacy Concerns
As mentioned, to do centralized learning, all the data would need to be sent to one server for compute. This, of course, raises privacy concerns, especially if the training data contains some sensitive information about an user. For example, a keyboard suggestions model would need to collect data on what an user types.
The solution proposed by Google (McMahan et al. 2016) is to distribute the data and the training. Continuing from the keyboard suggestion model, all the data would stay on the user’s phone, and the model training will happen on the device as well. They dubbed their method Federated Learning. Since its introduction by Google, some other big companies have used federated learning as well, including Apple, NVIDIA, and Amazon Web Services.
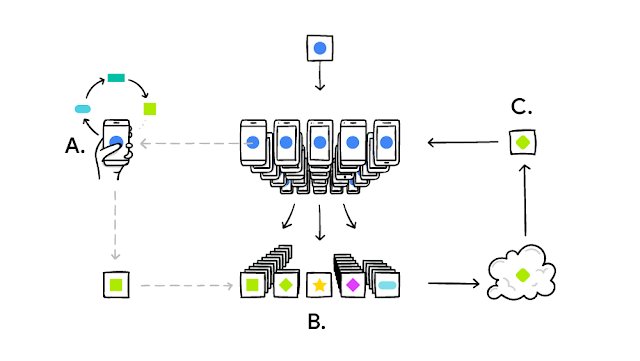
The next parts will outline how to do federated learning.
Federated Learning
Federated learning is a procedure where training takes place locally so that there is no need to send data out of the local device. In this process, there will be a centralized server (say, the Google server), and there will be K clients (say K Android users).
Learning takes place as follows:
- Initialization: At the start of the process, the federated learning server will send a global model (i.e: weights) to the clients. This model could be a pre-trained keyboard suggestion model trained on some public dataset.
- Local training: The clients will perform training (i.e: gradient descent update steps) using their local data.
- Transmission: The clients will send the updated weights back to the server.
- Aggregation: The server will take the weighted average of the received models from clients to be the new global model.
The process is repeated until convergence or after some predefined number of steps.
As you can see, only the model weights are sent to the server, the data stays on the users’ phones.
Local Training with FedSGD
When the model is trained on a single device, we simply calculate the loss function for that client. And the loss function for the global model is the weighted average of all local losses (*). Intuitively, a client with more data points will contribute more towards the global loss.

When performing gradient descent, the global weights is updated using the weighted average of the local gradients (gradients calculated on local data).

This is done iteratively until… well you get the point.
(*) This assumes that data across clients are i.i.d (independently and identically distributed). In practice, it is often the case some some client data are skewed (Zhao et al. 2018), which causes divergence problems. For possible remedy using FedProx, see Li et al. 2020.
Reducing Communication Rounds with FedAvg
In the simple FedSGD algorithm, each gradient descent step will incur one round of transmission. Imagine training a model with 100 epochs, that means all clients will have to send (and receive) model weights 100 times. This is inefficient (and for that matter, increases privacy risks that I won’t elaborate here).
To reduce the number of communication rounds, we can perform multiple gradient descent updates locally. And afterwards, we use a weighted average of all the local models as the new global model.

Notice that with FedSGD, the local gradients are sent back to the server, whereas in FedAvg, the local weights (updated after several epochs) are sent instead. Moreover, the gradients are only transmitted after some number of epochs (as opposed to every epoch), thus reducing the number of communication rounds.
Challenges
While federated learning reduces privacy risks by keeping the data local while training the model instead of sending it to the server, it is still vulnerable to some other types of attack such as gradient inversion attack (Geiping et al. 2020) or membership inference attack. I will leave the of elaboration these risks as well as potential defenses to my future self as homework. (It literally is my homework, due in about 5 days).
References
[1] McMahan, B., Moore, E., Ramage, D., Hampson, S. & Arcas, B.A.y.. (2017). Communication-Efficient Learning of Deep Networks from Decentralized Data. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, in Proceedings of Machine Learning Research 54:1273-1282
[2] Geiping, J., Bauermeister, H., Dröge, H., & Moeller, M. (2020). Inverting gradients-how easy is it to break privacy in federated learning?. Advances in neural information processing systems, 33, 16937-16947.
[3] Zhao, Y., Li, M., Lai, L., Suda, N., Civin, D., & Chandra, V. (2018). Federated learning with non-iid data. arXiv preprint arXiv:1806.00582.
[4] Li, T., Sahu, A. K., Zaheer, M., Sanjabi, M., Talwalkar, A., & Smith, V. (2020). Federated optimization in heterogeneous networks. Proceedings of Machine learning and systems, 2, 429-450.
[5] Federated Learning: Collaborative Machine Learning without Centralized Training Data